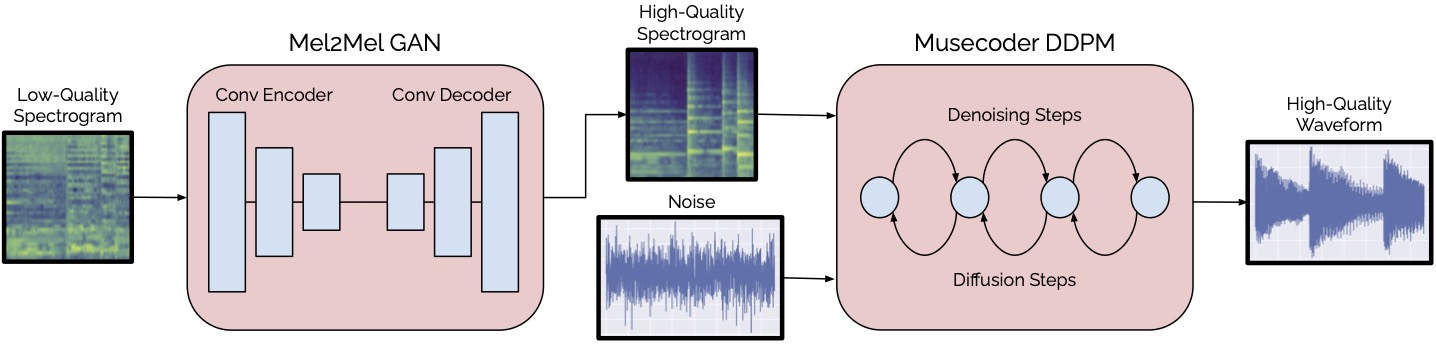
Consumer-grade music recordings such as those captured by mobile devices typically contain distortions in the form of background noise, reverb, and microphone-induced EQ. This paper presents a deep learning approach to enhance low-quality music recordings by combining (i) an image-to-image translation model for manipulating audio in its mel-spectrogram representation and (ii) a music vocoding model for mapping synthetically generated mel-spectrograms to perceptually realistic waveforms. We find that this approach to music enhancement outperforms baselines which use classical methods for mel-spectrogram inversion and an end-to-end approach directly mapping noisy waveforms to clean waveforms. Additionally, in evaluating the proposed method with a listening test, we analyze the reliability of common audio enhancement evaluation metrics when used in the music domain.
Real-World Samples
Below, we share a few representative samples generated by our best performing model, Mel2Mel + Diffwave, on real-world samples sourced from Youtube.
Additionally, we share test samples generated by all of the models we evaluate in the paper: Mel2Mel + Diffwave, Mel2Mel +
Griffin-Lim, and Demucs. Each row in the table contains the ground-truth high-quality recording from the Medley-Solos DB test set, the
simulated low-quality recording, and the reconstruction generated by each model.